You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.

Distributed¶
As we have seen so far, Dask allows you to simply construct graphs of tasks with dependencies, as well as have graphs created automatically for you using functional, Numpy or Pandas syntax on data collections. None of this would be very useful, if there weren’t also a way to execute these graphs, in a parallel and memory-aware way. So far we have been calling thing.compute() or dask.compute(thing) without worrying what this entails. Now we will discuss the options available for that
execution, and in particular, the distributed scheduler, which comes with additional functionality.
Dask comes with four available schedulers: - “threaded” (aka “threading”): a scheduler backed by a thread pool - “processes”: a scheduler backed by a process pool - “single-threaded” (aka “sync”): a synchronous scheduler, good for debugging - distributed: a distributed scheduler for executing graphs on multiple machines, see below.
To select one of these for computation, you can specify at the time of asking for a result, e.g.,
myvalue.compute(scheduler="single-threaded") # for debugging
You can also set a default scheduler either temporarily
with dask.config.set(scheduler='processes'):
# set temporarily for this block only
# all compute calls within this block will use the specified scheduler
myvalue.compute()
anothervalue.compute()
Or globally
# set until further notice
dask.config.set(scheduler='processes')
Let’s try out a few schedulers on the familiar case of the flights data.
[1]:
%run prep.py -d flights
[2]:
import dask.dataframe as dd
import os
df = dd.read_csv(os.path.join('data', 'nycflights', '*.csv'),
parse_dates={'Date': [0, 1, 2]},
dtype={'TailNum': object,
'CRSElapsedTime': float,
'Cancelled': bool})
# Maximum average non-cancelled delay grouped by Airport
largest_delay = df[~df.Cancelled].groupby('Origin').DepDelay.mean().max()
largest_delay
[2]:
dd.Scalar<series-..., dtype=float64>
[3]:
# each of the following gives the same results (you can check!)
# any surprises?
import time
for sch in ['threading', 'processes', 'sync']:
t0 = time.time()
r = largest_delay.compute(scheduler=sch)
t1 = time.time()
print(f"{sch:>10}, {t1 - t0:0.4f} s; result, {r:0.2f} hours")
threading, 0.1404 s; result, 17.05 hours
processes, 0.9771 s; result, 17.05 hours
sync, 0.1225 s; result, 17.05 hours
Some Questions to Consider:¶
How much speedup is possible for this task (hint, look at the graph).
Given how many cores are on this machine, how much faster could the parallel schedulers be than the single-threaded scheduler.
How much faster was using threads over a single thread? Why does this differ from the optimal speedup?
Why is the multiprocessing scheduler so much slower here?
The threaded scheduler is a fine choice for working with large datasets out-of-core on a single machine, as long as the functions being used release the GIL most of the time. NumPy and pandas release the GIL in most places, so the threaded scheduler is the default for dask.array and dask.dataframe. The distributed scheduler, perhaps with processes=False, will also work well for these workloads on a single machine.
For workloads that do hold the GIL, as is common with dask.bag and custom code wrapped with dask.delayed, we recommend using the distributed scheduler, even on a single machine. Generally speaking, it’s more intelligent and provides better diagnostics than the processes scheduler.
https://docs.dask.org/en/latest/scheduling.html provides some additional details on choosing a scheduler.
For scaling out work across a cluster, the distributed scheduler is required.
Making a cluster¶
Simple method¶
The dask.distributed system is composed of a single centralized scheduler and one or more worker processes. Deploying a remote Dask cluster involves some additional effort. But doing things locally is just involves creating a Client object, which lets you interact with the “cluster” (local threads or processes on your machine). For more information see here.
Note that Client() takes a lot of optional arguments, to configure the number of processes/threads, memory limits and other
[4]:
from dask.distributed import Client
# Setup a local cluster.
# By default this sets up 1 worker per core
client = Client()
client.cluster
If you aren’t in jupyterlab and using the dask-labextension, be sure to click the Dashboard link to open up the diagnostics dashboard.
Executing with the distributed client¶
Consider some trivial calculation, such as we’ve used before, where we have added sleep statements in order to simulate real work being done.
[5]:
from dask import delayed
import time
def inc(x):
time.sleep(5)
return x + 1
def dec(x):
time.sleep(3)
return x - 1
def add(x, y):
time.sleep(7)
return x + y
By default, creating a Client makes it the default scheduler. Any calls to .compute will use the cluster your client is attached to, unless you specify otherwise, as above.
[6]:
x = delayed(inc)(1)
y = delayed(dec)(2)
total = delayed(add)(x, y)
total.compute()
[6]:
3
The tasks will appear in the web UI as they are processed by the cluster and, eventually, a result will be printed as output of the cell above. Note that the kernel is blocked while waiting for the result. The resulting tasks block graph might look something like below. Hovering over each block gives which function it related to, and how long it took to execute. 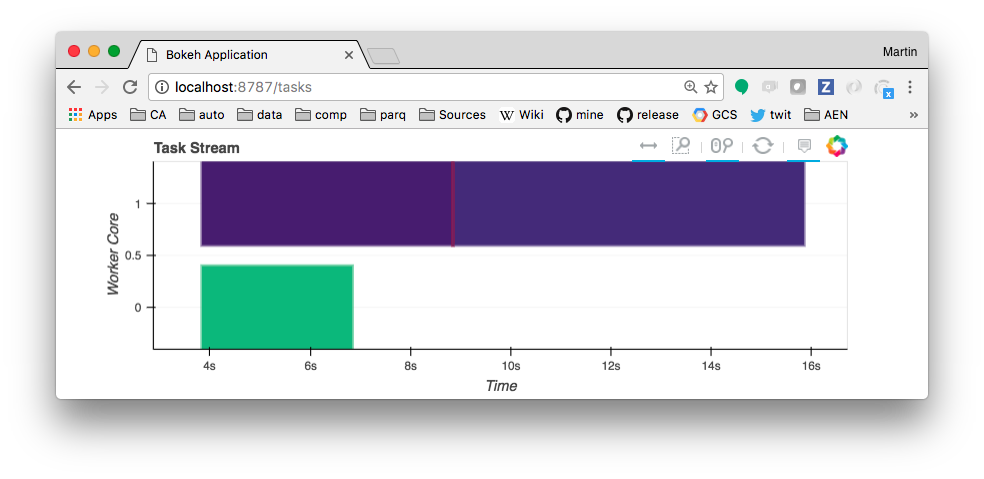
You can also see a simplified version of the graph being executed on Graph pane of the dashboard, so long as the calculation is in-flight.
Let’s return to the flights computation from before, and see what happens on the dashboard (you may wish to have both the notebook and dashboard side-by-side). How did does this perform compared to before?
[7]:
%time largest_delay.compute()
CPU times: user 56.7 ms, sys: 5.54 ms, total: 62.2 ms
Wall time: 624 ms
[7]:
17.053456221198157
In this particular case, this should be as fast or faster than the best case, threading, above. Why do you suppose this is? You should start your reading here, and in particular note that the distributed scheduler was a complete rewrite with more intelligence around sharing of intermediate results and which tasks run on which worker. This will result in better performance in some cases, but still larger latency and overhead compared to the threaded scheduler, so there will be rare cases where it performs worse. Fortunately, the dashboard now gives us a lot more diagnostic information. Look at the Profile page of the dashboard to find out what takes the biggest fraction of CPU time for the computation we just performed?
If all you want to do is execute computations created using delayed, or run calculations based on the higher-level data collections, then that is about all you need to know to scale your work up to cluster scale. However, there is more detail to know about the distributed scheduler that will help with efficient usage. See the chapter Distributed, Advanced.
Exercise¶
Run the following computations while looking at the diagnostics page. In each case what is taking the most time?
[8]:
# Number of flights
_ = len(df)
[9]:
# Number of non-cancelled flights
_ = len(df[~df.Cancelled])
[10]:
# Number of non-cancelled flights per-airport
_ = df[~df.Cancelled].groupby('Origin').Origin.count().compute()
[11]:
# Average departure delay from each airport?
_ = df[~df.Cancelled].groupby('Origin').DepDelay.mean().compute()
[12]:
# Average departure delay per day-of-week
_ = df.groupby(df.Date.dt.dayofweek).DepDelay.mean().compute()
[13]:
client.shutdown()