You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.

Lazy execution¶
Here we discuss some of the concepts behind dask, and lazy execution of code. You do not need to go through this material if you are eager to get on with the tutorial, but it may help understand the concepts underlying dask, how these things fit in with techniques you might already be using, and how to understand things that can go wrong.
Prelude¶
As Python programmers, you probably already perform certain tricks to enable computation of larger-than-memory datasets, parallel execution or delayed/background execution. Perhaps with this phrasing, it is not clear what we mean, but a few examples should make things clearer. The point of Dask is to make simple things easy and complex things possible!
Aside from the detailed introduction, we can summarize the basics of Dask as follows:
process data that doesn’t fit into memory by breaking it into blocks and specifying task chains
parallelize execution of tasks across cores and even nodes of a cluster
move computation to the data rather than the other way around, to minimize communication overhead
All of this allows you to get the most out of your computation resources, but program in a way that is very familiar: for-loops to build basic tasks, Python iterators, and the NumPy (array) and Pandas (dataframe) functions for multi-dimensional or tabular data, respectively.
The remainder of this notebook will take you through the first of these programming paradigms. This is more detail than some users will want, who can skip ahead to the iterator, array and dataframe sections; but there will be some data processing tasks that don’t easily fit into those abstractions and need to fall back to the methods here.
We include a few examples at the end of the notebooks showing that the ideas behind how Dask is built are not actually that novel, and experienced programmers will have met parts of the design in other situations before. Those examples are left for the interested.
Dask is a graph execution engine¶
Dask allows you to construct a prescription for the calculation you want to carry out. That may sound strange, but a simple example will demonstrate that you can achieve this while programming with perfectly ordinary Python functions and for-loops. We saw this in the previous notebook.
[1]:
from dask import delayed
@delayed
def inc(x):
return x + 1
@delayed
def add(x, y):
return x + y
Here we have used the delayed annotation to show that we want these functions to operate lazily — to save the set of inputs and execute only on demand. dask.delayed is also a function which can do this, without the annotation, leaving the original function unchanged, e.g.,
delayed_inc = delayed(inc)
[2]:
# this looks like ordinary code
x = inc(15)
y = inc(30)
total = add(x, y)
# x, y and total are all delayed objects.
# They contain a prescription of how to carry out the computation
Calling a delayed function created a delayed object (x, y, total) which can be examined interactively. Making these objects is somewhat equivalent to constructs like the lambda or function wrappers (see below). Each holds a simple dictionary describing the task graph, a full specification of how to carry out the computation.
We can visualize the chain of calculations that the object total corresponds to as follows; the circles are functions, rectangles are data/results.
[3]:
total.visualize()
[3]:
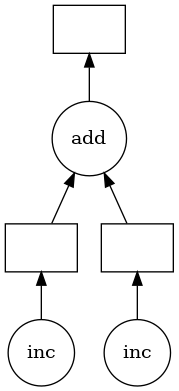
But so far, no functions have actually been executed. This demonstrated the division between the graph-creation part of Dask (delayed(), in this example) and the graph execution part of Dask.
To run the “graph” in the visualization, and actually get a result, do:
[4]:
# execute all tasks
total.compute()
[4]:
47
Why should you care about this?
By building a specification of the calculation we want to carry out before executing anything, we can pass the specification to an execution engine for evaluation. In the case of Dask, this execution engine could be running on many nodes of a cluster, so you have access to the full number of CPU cores and memory across all the machines. Dask will intelligently execute your calculation with care for minimizing the amount of data held in memory, while parallelizing over the tasks that make up a graph. Notice that in the animated diagram below, where four workers are processing the (simple) graph, execution progresses vertically up the branches first, so that intermediate results can be expunged before moving onto a new branch.
With delayed and normal pythonic looped code, very complex graphs can be built up and passed on to Dask for execution. See a nice example of simulated complex ETL work flow.
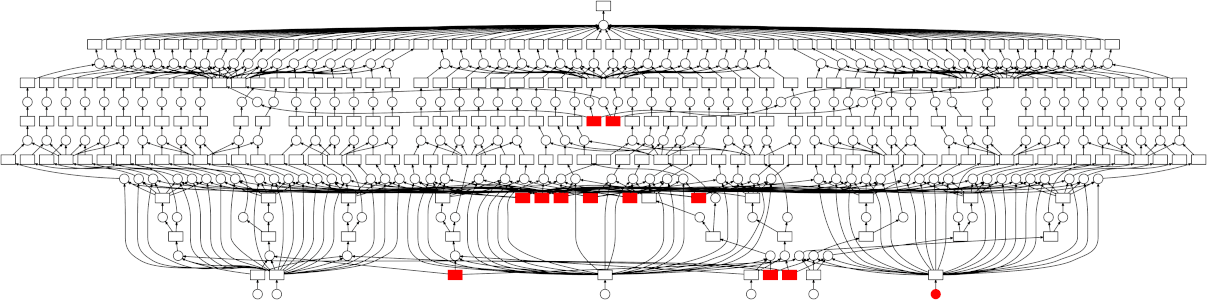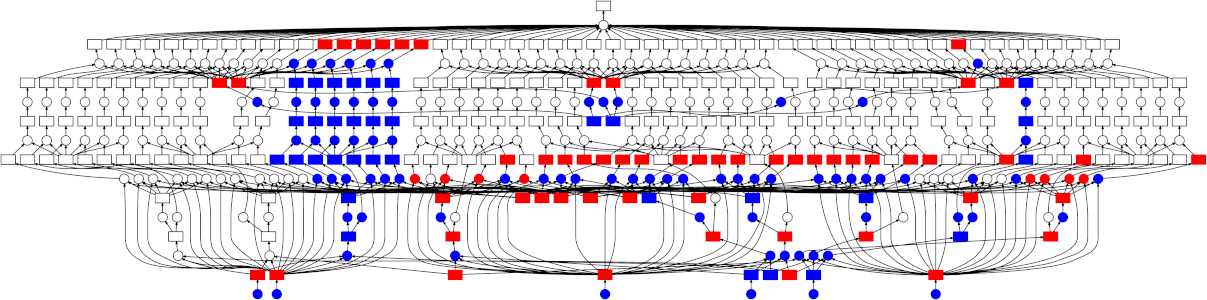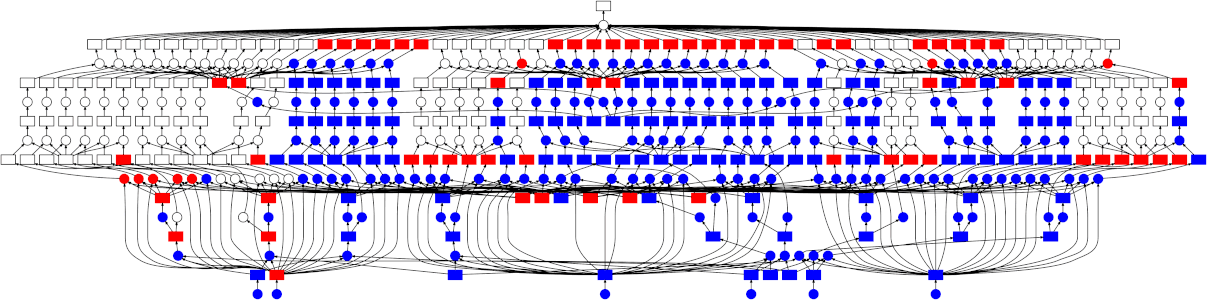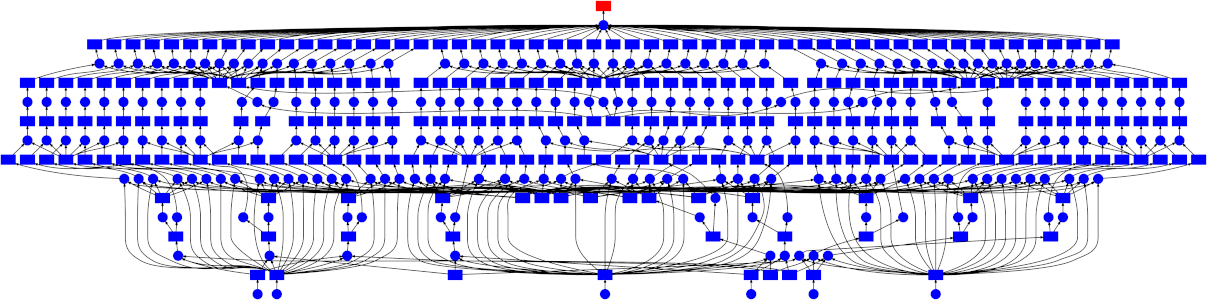
Exercise¶
We will apply delayed to a real data processing task, albeit a simple one.
Consider reading three CSV files with pd.read_csv and then measuring their total length. We will consider how you would do this with ordinary Python code, then build a graph for this process using delayed, and finally execute this graph using Dask, for a handy speed-up factor of more than two (there are only three inputs to parallelize over).
[5]:
%run prep.py -d accounts
[6]:
import pandas as pd
import os
filenames = [os.path.join('data', 'accounts.%d.csv' % i) for i in [0, 1, 2]]
filenames
[6]:
['data/accounts.0.csv', 'data/accounts.1.csv', 'data/accounts.2.csv']
[7]:
%%time
# normal, sequential code
a = pd.read_csv(filenames[0])
b = pd.read_csv(filenames[1])
c = pd.read_csv(filenames[2])
na = len(a)
nb = len(b)
nc = len(c)
total = sum([na, nb, nc])
print(total)
30000
CPU times: user 11.3 ms, sys: 7.9 ms, total: 19.2 ms
Wall time: 18.9 ms
Your task is to recreate this graph again using the delayed function on the original Python code. The three functions you want to delay are pd.read_csv, len and sum..
delayed_read_csv = delayed(pd.read_csv)
a = delayed_read_csv(filenames[0])
...
total = ...
# execute
%time total.compute()
[8]:
# your verbose code here
Next, repeat this using loops, rather than writing out all the variables.
[9]:
# your concise code here
[10]:
## verbose version
delayed_read_csv = delayed(pd.read_csv)
a = delayed_read_csv(filenames[0])
b = delayed_read_csv(filenames[1])
c = delayed_read_csv(filenames[2])
delayed_len = delayed(len)
na = delayed_len(a)
nb = delayed_len(b)
nc = delayed_len(c)
delayed_sum = delayed(sum)
total = delayed_sum([na, nb, nc])
%time print(total.compute())
## concise version
csvs = [delayed(pd.read_csv)(fn) for fn in filenames]
lens = [delayed(len)(csv) for csv in csvs]
total = delayed(sum)(lens)
%time print(total.compute())
30000
CPU times: user 14.3 ms, sys: 8.43 ms, total: 22.7 ms
Wall time: 15.4 ms
30000
CPU times: user 20.3 ms, sys: 680 µs, total: 21 ms
Wall time: 15.6 ms
Notes
Delayed objects support various operations:
x2 = x + 1
if x was a delayed result (like total, above), then so is x2. Supported operations include arithmetic operators, item or slice selection, attribute access and method calls - essentially anything that could be phrased as a lambda expression.
Operations which are not supported include mutation, setter methods, iteration (for) and bool (predicate).
Appendix: Further detail and examples¶
The following examples show that the kinds of things Dask does are not so far removed from normal Python programming when dealing with big data. These examples are only meant for experts, typical users can continue with the next notebook in the tutorial.
Example 1: simple word count¶
This directory contains a file called README.md. How would you count the number of words in that file?
The simplest approach would be to load all the data into memory, split on whitespace and count the number of results. Here we use a regular expression to split words.
[11]:
import re
splitter = re.compile('\w+')
with open('README.md', 'r') as f:
data = f.read()
result = len(splitter.findall(data))
result
[11]:
747
The trouble with this approach is that it does not scale - if the file is very large, it, and the generated list of words, might fill up memory. We can easily avoid that, because we only need a simple sum, and each line is totally independent of the others. Now we evaluate each piece of data and immediately free up the space again, so we could perform this on arbitrarily-large files. Note that there is often a trade-off between time-efficiency and memory footprint: the following uses very little memory, but may be slower for files that do not fill a large faction of memory. In general, one would like chunks small enough not to stress memory, but big enough for efficient use of the CPU.
[12]:
result = 0
with open('README.md', 'r') as f:
for line in f:
result += len(splitter.findall(line))
result
[12]:
747
Example 2: background execution¶
There are many tasks that take a while to complete, but don’t actually require much of the CPU, for example anything that requires communication over a network, or input from a user. In typical sequential programming, execution would need to halt while the process completes, and then continue execution. That would be dreadful for user experience (imagine the slow progress bar that locks up the application and cannot be canceled), and wasteful of time (the CPU could have been doing useful work in the meantime).
For example, we can launch processes and get their output as follows:
import subprocess
p = subprocess.Popen(command, stdout=subprocess.PIPE)
p.returncode
The task is run in a separate process, and the return-code will remain None until it completes, when it will change to 0. To get the result back, we need out = p.communicate()[0] (which would block if the process was not complete).
Similarly, we can launch Python processes and threads in the background. Some methods allow mapping over multiple inputs and gathering the results, more on that later. The thread starts and the cell completes immediately, but the data associated with the download only appears in the queue object some time later.
[13]:
# Edit sources.py to configure source locations
import sources
sources.lazy_url
[13]:
'http://www.google.com'
[14]:
import threading
import queue
import urllib
def get_webdata(url, q):
u = urllib.request.urlopen(url)
# raise ValueError
q.put(u.read())
q = queue.Queue()
t = threading.Thread(target=get_webdata, args=(sources.lazy_url, q))
t.start()
[15]:
# fetch result back into this thread. If the worker thread is not done, this would wait.
q.get()
[15]:
b'<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world\'s information, including webpages, images, videos and more. Google has many special features to help you find exactly what you\'re looking for." name="description"><meta content="noodp" name="robots"><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title><script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){window.google={kEI:\'_u72YKDuH_Ol1QHMmo7wBQ\',kEXPI:\'0,772215,1,530320,56873,954,5105,206,4804,2316,383,246,5,1354,4936,315,1122515,1197720,563,328984,51224,16114,28684,17572,4858,1362,9290,3021,17588,4020,978,13228,3847,10622,1142,13386,4517,2777,919,5081,1593,1279,2212,530,149,1103,840,1983,213,4101,109,3405,606,2023,1777,520,14670,3227,1990,855,7,4774,7580,5096,7876,5037,1483,1372,553,907,2,941,6397,8927,432,3,1590,1,5444,149,11323,2652,4,1528,2304,1236,5226,577,74,1983,2627,2014,4,11497,2110,1714,1011,2039,2658,4242,3114,31,13628,2305,638,37,1457,5587,3771,5993,770,665,2522,3275,2332,228,992,3102,20,3118,6,908,3,3541,1,5349,6594,2767,1,1813,283,38,874,5998,12520,2,1394,756,769,8,1,1272,1715,2,3057,2538,1,2,2,3612,12,615,4,32,4,2237,2,3148,4,683,442,342,255,55,4,434,2377,93,30,520,1780,1275,4578,1576,3,472,577,3,1066,172,5005,446,100,3,363,677,1160,1102,167,3425,3,1711,291,1474,59,848,1575,1142,3710,2,333,2,500,3,125,747,3105,1496,13,1448,2432,1,12,3,1,1478,72,223,1899,228,402,45,1,8,46,1,8,23,2186,118,394,967,1,2,1026,6,123,899,1513,106,316,470,85,57,268,562,333,158,190,153,416,1064,3,468,342,1386,520,3,1258,2546,467,1318,852,61,892,2023,2,1647,1,5610037,99,2,93,32,220,59,1,5996808,2799373,1324,882,444,1,2,80,1,1796,1,9,2,2551,1,748,141,795,563,1,4265,1,1,2,1331,3299,843,2609,155,17,13,72,139,4,2,20,2,169,13,19,46,5,39,96,548,29,2,2,1,2,1,2,2,7,4,1,2,2,2,2,2,2,312,41,513,186,1,1,158,3,2,2,2,2,2,4,2,3,3,233,36,21,38,1874713,21780085,299866,2738464,1273912,28975,338,3,2339,75,541,365,7,95,1571,210,259,772077\',kBL:\'rUkx\'};google.sn=\'webhp\';google.kHL=\'en\';})();(function(){\nvar f=this||self;var h,k=[];function l(a){for(var b;a&&(!a.getAttribute||!(b=a.getAttribute("eid")));)a=a.parentNode;return b||h}function m(a){for(var b=null;a&&(!a.getAttribute||!(b=a.getAttribute("leid")));)a=a.parentNode;return b}\nfunction n(a,b,c,d,g){var e="";c||-1!==b.search("&ei=")||(e="&ei="+l(d),-1===b.search("&lei=")&&(d=m(d))&&(e+="&lei="+d));d="";!c&&f._cshid&&-1===b.search("&cshid=")&&"slh"!==a&&(d="&cshid="+f._cshid);c=c||"/"+(g||"gen_204")+"?atyp=i&ct="+a+"&cad="+b+e+"&zx="+Date.now()+d;/^http:/i.test(c)&&"https:"===window.location.protocol&&(google.ml&&google.ml(Error("a"),!1,{src:c,glmm:1}),c="");return c};h=google.kEI;google.getEI=l;google.getLEI=m;google.ml=function(){return null};google.log=function(a,b,c,d,g){if(c=n(a,b,c,d,g)){a=new Image;var e=k.length;k[e]=a;a.onerror=a.onload=a.onabort=function(){delete k[e]};a.src=c}};google.logUrl=n;}).call(this);(function(){\ngoogle.y={};google.sy=[];google.x=function(a,b){if(a)var c=a.id;else{do c=Math.random();while(google.y[c])}google.y[c]=[a,b];return!1};google.sx=function(a){google.sy.push(a)};google.lm=[];google.plm=function(a){google.lm.push.apply(google.lm,a)};google.lq=[];google.load=function(a,b,c){google.lq.push([[a],b,c])};google.loadAll=function(a,b){google.lq.push([a,b])};google.bx=!1;google.lx=function(){};}).call(this);google.f={};(function(){\ndocument.documentElement.addEventListener("submit",function(b){var a;if(a=b.target){var c=a.getAttribute("data-submitfalse");a="1"==c||"q"==c&&!a.elements.q.value?!0:!1}else a=!1;a&&(b.preventDefault(),b.stopPropagation())},!0);document.documentElement.addEventListener("click",function(b){var a;a:{for(a=b.target;a&&a!=document.documentElement;a=a.parentElement)if("A"==a.tagName){a="1"==a.getAttribute("data-nohref");break a}a=!1}a&&b.preventDefault()},!0);}).call(this);</script><style>#gbar,#guser{font-size:13px;padding-top:1px !important;}#gbar{height:22px}#guser{padding-bottom:7px !important;text-align:right}.gbh,.gbd{border-top:1px solid #c9d7f1;font-size:1px}.gbh{height:0;position:absolute;top:24px;width:100%}@media all{.gb1{height:22px;margin-right:.5em;vertical-align:top}#gbar{float:left}}a.gb1,a.gb4{text-decoration:underline !important}a.gb1,a.gb4{color:#00c !important}.gbi .gb4{color:#dd8e27 !important}.gbf .gb4{color:#900 !important}\n</style><style>body,td,a,p,.h{font-family:arial,sans-serif}body{margin:0;overflow-y:scroll}#gog{padding:3px 8px 0}td{line-height:.8em}.gac_m td{line-height:17px}form{margin-bottom:20px}.h{color:#1558d6}em{font-weight:bold;font-style:normal}.lst{height:25px;width:496px}.gsfi,.lst{font:18px arial,sans-serif}.gsfs{font:17px arial,sans-serif}.ds{display:inline-box;display:inline-block;margin:3px 0 4px;margin-left:4px}input{font-family:inherit}body{background:#fff;color:#000}a{color:#4b11a8;text-decoration:none}a:hover,a:active{text-decoration:underline}.fl a{color:#1558d6}a:visited{color:#4b11a8}.sblc{padding-top:5px}.sblc a{display:block;margin:2px 0;margin-left:13px;font-size:11px}.lsbb{background:#f8f9fa;border:solid 1px;border-color:#dadce0 #70757a #70757a #dadce0;height:30px}.lsbb{display:block}#WqQANb a{display:inline-block;margin:0 12px}.lsb{background:url(/images/nav_logo229.png) 0 -261px repeat-x;border:none;color:#000;cursor:pointer;height:30px;margin:0;outline:0;font:15px arial,sans-serif;vertical-align:top}.lsb:active{background:#dadce0}.lst:focus{outline:none}</style><script nonce="BX7rVj4lqNTuUHmH2mU/8w=="></script></head><body bgcolor="#fff"><script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){var src=\'/images/nav_logo229.png\';var iesg=false;document.body.onload = function(){window.n && window.n();if (document.images){new Image().src=src;}\nif (!iesg){document.f&&document.f.q.focus();document.gbqf&&document.gbqf.q.focus();}\n}\n})();</script><div id="mngb"><div id=gbar><nobr><b class=gb1>Search</b> <a class=gb1 href="http://www.google.com/imghp?hl=en&tab=wi">Images</a> <a class=gb1 href="http://maps.google.com/maps?hl=en&tab=wl">Maps</a> <a class=gb1 href="https://play.google.com/?hl=en&tab=w8">Play</a> <a class=gb1 href="http://www.youtube.com/?gl=US&tab=w1">YouTube</a> <a class=gb1 href="https://news.google.com/?tab=wn">News</a> <a class=gb1 href="https://mail.google.com/mail/?tab=wm">Gmail</a> <a class=gb1 href="https://drive.google.com/?tab=wo">Drive</a> <a class=gb1 style="text-decoration:none" href="https://www.google.com/intl/en/about/products?tab=wh"><u>More</u> »</a></nobr></div><div id=guser width=100%><nobr><span id=gbn class=gbi></span><span id=gbf class=gbf></span><span id=gbe></span><a href="http://www.google.com/history/optout?hl=en" class=gb4>Web History</a> | <a href="/preferences?hl=en" class=gb4>Settings</a> | <a target=_top id=gb_70 href="https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=http://www.google.com/&ec=GAZAAQ" class=gb4>Sign in</a></nobr></div><div class=gbh style=left:0></div><div class=gbh style=right:0></div></div><center><br clear="all" id="lgpd"><div id="lga"><img alt="Google" height="92" src="/images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png" style="padding:28px 0 14px" width="272" id="hplogo"><br><br></div><form action="/search" name="f"><table cellpadding="0" cellspacing="0"><tr valign="top"><td width="25%"> </td><td align="center" nowrap=""><input name="ie" value="ISO-8859-1" type="hidden"><input value="en" name="hl" type="hidden"><input name="source" type="hidden" value="hp"><input name="biw" type="hidden"><input name="bih" type="hidden"><div class="ds" style="height:32px;margin:4px 0"><input class="lst" style="margin:0;padding:5px 8px 0 6px;vertical-align:top;color:#000" autocomplete="off" value="" title="Google Search" maxlength="2048" name="q" size="57"></div><br style="line-height:0"><span class="ds"><span class="lsbb"><input class="lsb" value="Google Search" name="btnG" type="submit"></span></span><span class="ds"><span class="lsbb"><input class="lsb" id="tsuid1" value="I\'m Feeling Lucky" name="btnI" type="submit"><script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){var id=\'tsuid1\';document.getElementById(id).onclick = function(){if (this.form.q.value){this.checked = 1;if (this.form.iflsig)this.form.iflsig.disabled = false;}\nelse top.location=\'/doodles/\';};})();</script><input value="AINFCbYAAAAAYPb9Dukmj9C36K76wfN4NgDQiNDQovra" name="iflsig" type="hidden"></span></span></td><td class="fl sblc" align="left" nowrap="" width="25%"><a href="/advanced_search?hl=en&authuser=0">Advanced search</a></td></tr></table><input id="gbv" name="gbv" type="hidden" value="1"><script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){\nvar a,b="1";if(document&&document.getElementById)if("undefined"!=typeof XMLHttpRequest)b="2";else if("undefined"!=typeof ActiveXObject){var c,d,e=["MSXML2.XMLHTTP.6.0","MSXML2.XMLHTTP.3.0","MSXML2.XMLHTTP","Microsoft.XMLHTTP"];for(c=0;d=e[c++];)try{new ActiveXObject(d),b="2"}catch(h){}}a=b;if("2"==a&&-1==location.search.indexOf("&gbv=2")){var f=google.gbvu,g=document.getElementById("gbv");g&&(g.value=a);f&&window.setTimeout(function(){location.href=f},0)};}).call(this);</script></form><div id="gac_scont"></div><div style="font-size:83%;min-height:3.5em"><br></div><span id="footer"><div style="font-size:10pt"><div style="margin:19px auto;text-align:center" id="WqQANb"><a href="/intl/en/ads/">Advertising\xa0Programs</a><a href="/services/">Business Solutions</a><a href="/intl/en/about.html">About Google</a></div></div><p style="font-size:8pt;color:#70757a">© 2021 - <a href="/intl/en/policies/privacy/">Privacy</a> - <a href="/intl/en/policies/terms/">Terms</a></p></span></center><script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){window.google.cdo={height:757,width:1440};(function(){\nvar a=window.innerWidth,b=window.innerHeight;if(!a||!b){var c=window.document,d="CSS1Compat"==c.compatMode?c.documentElement:c.body;a=d.clientWidth;b=d.clientHeight}a&&b&&(a!=google.cdo.width||b!=google.cdo.height)&&google.log("","","/client_204?&atyp=i&biw="+a+"&bih="+b+"&ei="+google.kEI);}).call(this);})();</script> <script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){google.xjs={ck:\'\',cs:\'\',excm:[],pml:false};})();</script> <script nonce="BX7rVj4lqNTuUHmH2mU/8w==">(function(){var u=\'/xjs/_/js/k\\x3dxjs.hp.en_US.uG5gNub4OSM.O/m\\x3dsb_he,d/am\\x3dAHgCLA/d\\x3d1/ed\\x3d1/rs\\x3dACT90oE5mpOHNMzK1ifCe0jZfTofWVvTxQ\';\nvar e=this||self,f=function(a){return a};var g;var l=function(a,b){this.g=b===h?a:""};l.prototype.toString=function(){return this.g+""};var h={};function m(){var a=u;google.lx=function(){n(a);google.lx=function(){}};google.bx||google.lx()}\nfunction n(a){google.timers&&google.timers.load&&google.tick&&google.tick("load","xjsls");var b=document;var c="SCRIPT";"application/xhtml+xml"===b.contentType&&(c=c.toLowerCase());c=b.createElement(c);if(void 0===g){b=null;var k=e.trustedTypes;if(k&&k.createPolicy){try{b=k.createPolicy("goog#html",{createHTML:f,createScript:f,createScriptURL:f})}catch(p){e.console&&e.console.error(p.message)}g=b}else g=b}a=(b=g)?b.createScriptURL(a):a;a=new l(a,h);c.src=a instanceof l&&a.constructor===l?a.g:"type_error:TrustedResourceUrl";var d;a=(c.ownerDocument&&c.ownerDocument.defaultView||window).document;(d=(a=null===(d=a.querySelector)||void 0===d?void 0:d.call(a,"script[nonce]"))?a.nonce||a.getAttribute("nonce")||"":"")&&c.setAttribute("nonce",d);document.body.appendChild(c);google.psa=!0};setTimeout(function(){m()},0);})();(function(){window.google.xjsu=\'/xjs/_/js/k\\x3dxjs.hp.en_US.uG5gNub4OSM.O/m\\x3dsb_he,d/am\\x3dAHgCLA/d\\x3d1/ed\\x3d1/rs\\x3dACT90oE5mpOHNMzK1ifCe0jZfTofWVvTxQ\';})();function _DumpException(e){throw e;}\nfunction _F_installCss(c){}\n(function(){google.jl={attn:false,blt:\'none\',chnk:0,dw:false,emtn:0,end:0,ine:false,lls:\'default\',pdt:0,rep:0,snet:true,strt:0,ubm:false,uwp:true};})();(function(){var pmc=\'{\\x22d\\x22:{},\\x22sb_he\\x22:{\\x22agen\\x22:true,\\x22cgen\\x22:true,\\x22client\\x22:\\x22heirloom-hp\\x22,\\x22dh\\x22:true,\\x22dhqt\\x22:true,\\x22ds\\x22:\\x22\\x22,\\x22ffql\\x22:\\x22en\\x22,\\x22fl\\x22:true,\\x22host\\x22:\\x22google.com\\x22,\\x22isbh\\x22:28,\\x22jsonp\\x22:true,\\x22msgs\\x22:{\\x22cibl\\x22:\\x22Clear Search\\x22,\\x22dym\\x22:\\x22Did you mean:\\x22,\\x22lcky\\x22:\\x22I\\\\u0026#39;m Feeling Lucky\\x22,\\x22lml\\x22:\\x22Learn more\\x22,\\x22oskt\\x22:\\x22Input tools\\x22,\\x22psrc\\x22:\\x22This search was removed from your \\\\u003Ca href\\x3d\\\\\\x22/history\\\\\\x22\\\\u003EWeb History\\\\u003C/a\\\\u003E\\x22,\\x22psrl\\x22:\\x22Remove\\x22,\\x22sbit\\x22:\\x22Search by image\\x22,\\x22srch\\x22:\\x22Google Search\\x22},\\x22ovr\\x22:{},\\x22pq\\x22:\\x22\\x22,\\x22refpd\\x22:true,\\x22rfs\\x22:[],\\x22sbas\\x22:\\x220 3px 8px 0 rgba(0,0,0,0.2),0 0 0 1px rgba(0,0,0,0.08)\\x22,\\x22sbpl\\x22:16,\\x22sbpr\\x22:16,\\x22scd\\x22:10,\\x22stok\\x22:\\x22Y9DwG6g-m2DFXkEcUUnEerCaeq4\\x22,\\x22uhde\\x22:false}}\';google.pmc=JSON.parse(pmc);})();</script> </body></html>'
Consider: what would you see if there had been an exception within the get_webdata function? You could uncomment the raise line, above, and re-execute the two cells. What happens? Is there any way to debug the execution to find the root cause of the error?
Example 3: delayed execution¶
There are many ways in Python to specify the computation you want to execute, but only run it later.
[16]:
def add(x, y):
return x + y
# Sometimes we defer computations with strings
x = 15
y = 30
z = "add(x, y)"
eval(z)
[16]:
45
[17]:
# we can use lambda or other "closure"
x = 15
y = 30
z = lambda: add(x, y)
z()
[17]:
45
[18]:
# A very similar thing happens in functools.partial
import functools
z = functools.partial(add, x, y)
z()
[18]:
45
[19]:
# Python generators are delayed execution by default
# Many Python functions expect such iterable objects
def gen():
res = x
yield res
res += y
yield res
g = gen()
[20]:
# run once: we get one value and execution halts within the generator
# run again and the execution completes
next(g)
[20]:
15
Dask graphs¶
Any Dask object, such as total, above, has an attribute which describes the calculations necessary to produce that result. Indeed, this is exactly the graph that we have been talking about, which can be visualized. We see that it is a simple dictionary, in which the keys are unique task identifiers, and the values are the functions and inputs for calculation.
delayed is a handy mechanism for creating the Dask graph, but the adventurous may wish to play with the full fexibility afforded by building the graph dictionaries directly. Detailed information can be found here.
[21]:
total.dask
[21]:
<dask.highlevelgraph.HighLevelGraph at 0x7f07a3aaf850>
[22]:
dict(total.dask)
[22]:
{'sum-dbbfcbc4-8bbb-4271-9171-544c78ea5f26': (<function sum(iterable, /, start=0)>,
['len-d3795c25-bd8d-4e80-90c0-53978b80f9c4',
'len-704409d6-27bd-4fb9-9580-0c273fea1e51',
'len-9c97d4ab-3f62-40cf-8b6e-0f4ed1f41924']),
'read_csv-14ad1cdc-7e7b-44b0-8a9d-1fcdabac12e6': (<function pandas.io.parsers.readers.read_csv(filepath_or_buffer: 'FilePathOrBuffer', sep=<no_default>, delimiter=None, header='infer', names=<no_default>, index_col=None, usecols=None, squeeze=False, prefix=<no_default>, mangle_dupe_cols=True, dtype: 'DtypeArg | None' = None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal: 'str' = '.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors: 'str | None' = 'strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options: 'StorageOptions' = None)>,
'data/accounts.0.csv'),
'len-d3795c25-bd8d-4e80-90c0-53978b80f9c4': (<function len(obj, /)>,
'read_csv-14ad1cdc-7e7b-44b0-8a9d-1fcdabac12e6'),
'read_csv-3b1dc681-c4b5-4a42-bc5d-0a2544bc6b2f': (<function pandas.io.parsers.readers.read_csv(filepath_or_buffer: 'FilePathOrBuffer', sep=<no_default>, delimiter=None, header='infer', names=<no_default>, index_col=None, usecols=None, squeeze=False, prefix=<no_default>, mangle_dupe_cols=True, dtype: 'DtypeArg | None' = None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal: 'str' = '.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors: 'str | None' = 'strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options: 'StorageOptions' = None)>,
'data/accounts.1.csv'),
'len-704409d6-27bd-4fb9-9580-0c273fea1e51': (<function len(obj, /)>,
'read_csv-3b1dc681-c4b5-4a42-bc5d-0a2544bc6b2f'),
'read_csv-7f562652-57b1-413b-881d-0a526dffddd5': (<function pandas.io.parsers.readers.read_csv(filepath_or_buffer: 'FilePathOrBuffer', sep=<no_default>, delimiter=None, header='infer', names=<no_default>, index_col=None, usecols=None, squeeze=False, prefix=<no_default>, mangle_dupe_cols=True, dtype: 'DtypeArg | None' = None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal: 'str' = '.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors: 'str | None' = 'strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options: 'StorageOptions' = None)>,
'data/accounts.2.csv'),
'len-9c97d4ab-3f62-40cf-8b6e-0f4ed1f41924': (<function len(obj, /)>,
'read_csv-7f562652-57b1-413b-881d-0a526dffddd5')}